
R语言的链式操作
2023年5月25日
编程
如果说R语言做数据分析中有什么神器,那必定是来自 **magrittr** 包的“管道操作符”莫属。说实话,当习惯了使用管道操作符之后,再用 Pandas 经常会觉得麻烦,虽然 Pandas 也支持链式操作,但有些操作还是不支持的。本文介绍一下R语言中几种常用的管道操作符,一定会对数据分析体验有一个质的飞跃。
# 最重要的操作符: `%>%`
虽然R语言出了一个原生的管道运算符 `|>` ,而且字符数要少一个,但是功能是完全无法和 `%>%` 相比的。而且做数据分析的时候免不了要加载 **tidyverse** ,所以不如直接使用 `%>%` 运算符。该运算符非常重要,值得在 IDE 中给它安排一个快捷键。
## 示例
为了展示其作用,这里举一个例子。假设现在我们要对 iris 数据集进行分析。
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
| -------------- | ------------- | -------------- | ------------- | --------- |
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
| 4.6 | 3.4 | 1.4 | 0.3 | setosa |
| 5.0 | 3.4 | 1.5 | 0.2 | setosa |
首先我们要选出 Species 属性是 setosa 的部分,然后用 **ggplot** 绘制散点图。如果使用原生函数,有两种模式。一种是创建中间变量
```r
iris_setosa <- subset(iris, Species == "setosa")
ggplot(iris_setosa, aes(Sepal.Length, Sepal.Width)) + geom_point()
```
另一种是函数嵌套
```r
ggplot(subset(iris, Species == "setosa"), aes(Sepal.Length, Sepal.Width)) + geom_point()
```
这两种模式随着数据处理过程的增长,都有不方便的地方。前者会创建越来越多的中间变量,会占用大量内存;而且中间变量的命名是个问题,变量名不可避免地越来越长,既不便于书写,也不容易记忆。后者会让代码越来越长,非常不便于阅读,而且代码出了问题也不便于定位错误。
而如果用管道操作符,以上问题迎刃而解。
```r
subset(iris, Species == "setosa") %>%
ggplot(aes(Sepal.Length, Sepal.Width)) + geom_point()
```
既没有创建中间变量,也不会让代码变得非常长,甚至还缩短了代码长度,可谓是一箭双雕还送了只鸟。
如果和 **dplyr** 、 **purrr** 等包函数搭配使用,则非常方便
```r
iris %>%
filter(Species == "setosa") %>%
mutate(Sum.Length = Sepal.Length + Petal.Length) %>%
ggplot(aes(Sum.Length)) + geom_histogram(binwidth = 0.2)
```
以上代码执行了多个操作,但是没有产生任何中间变量,可读性也依然保持的很好。
## 原理分析
实际上,管道运算符 `%>%` 属于一个二元运算符,既然是二元运算符那就有左、右两个操作数,不妨设为 `L` 和 `R` 。对于 `L` 没有什么要求,只要是个 R 语言中的 object 就可以。但是,`R` 需要是一个可执行的函数。既然是函数,那就需要传递参数。如果是直接以 `L %>% R` 的模式写成的,那么 `L` 会被传递为 `R` 的第一个参数,其他写在 `R` 中的参数(假设是 `R(...)` )将依次作为后续参数传递,也就是相当于 `R(L, ...)` 。
那么如果 `R` 中不止第一个位置需要 `L` ,又或者 `L` 不是放在 `R` 的第一个参数位置上呢?此时可以使用 `.` 代替 `L` 进行参数传递。例如如果要对处理过的 iris 数据集中的 Sepal.Length 和 Sepal.Width 做回归,此时要将数据放在 `data` 的位置上,那么就可以使用以下几种方式:
```r
subset(iris, Species == "setosa") %>% lm(Sepal.Length ~ Sepal.Width, .) %>% summary()
subset(iris, Species == "setosa") %>% lm(Sepal.Length ~ Sepal.Width, data = .) %>% summary()
subset(iris, Species == "setosa") %>% lm(formula = Sepal.Length ~ Sepal.Width, data =.) %>% summary()
```
此时,参数 `L` 就不会出现在 `R` 的第一个参数位置上了。而且 `.` 是可以复用的,每个出现 `.` 的位置上,都会把 `L` 作为实参传递。例如,如果要统计 iris 四个测量值各自的总离差平方和($\sum (y_i-\bar{y})^2$)并用 **ggplot** 绘制成柱状图,就可以用下面的方式
```r
iris[,1:4] %>%
Map(function (x, y) {
data.frame(
indicator = y,
tss = sum((x - mean(x))^2)
)
}, ., names(.)) %>%
Reduce(rbind, .) %>%
ggplot(aes(x = indicator, y = tss)) + geom_col()
```
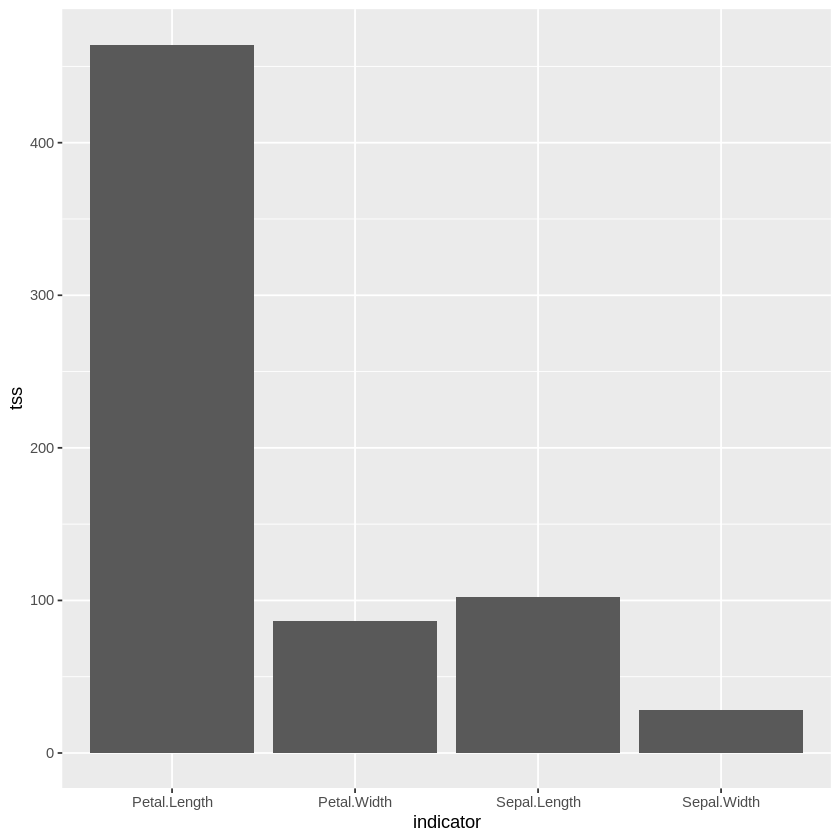
由于 **ggplot** 绘图使用的数据都是关系数据,所以这里不仅提取出前四列,也提取出前四列的名字,然后分别运算组合成一个包含两列的数据框,一列是 `indicator` 表示指标名,后面的 `tss` 表示该指标的总离差平方和。
# 特殊管道运算符
下面这些运算符需要明确加载 **magrittr** 包,只加载 **tidyverse** 是没有的。
## Tee Pipe `%T>%`
如果熟悉 Linux 则会了解一个命令 `tee` ,该命令可以将程序输出同时输出到控制台和标准输出,是非常有用的一个命令。而这个 Tee Pipe 也是类似的功能:它可以同时将一个 `L` 流向两个 `R` ,用法是
```r
L %T>% R1 %>% R2
```
这样在调用 `R2` 时,其左操作数不再是 `R1` 的返回值,而是 `L` 。在有些时候可以产生奇效,比如上一个例子,如果我们想在输出柱状图之前输出一下处理过的数据,就可以这样
```r
iris[,1:4] %>%
Map(function (x, y) {
data.frame(
indicator = y,
tss = sum((x - mean(x))^2)
)
}, ., names(.)) %>%
Reduce(rbind, .) %T>%
print() %>%
ggplot(aes(x = indicator, y = tss)) + geom_col()
```
或者用这种方式将图片同时输出到屏幕和文件
```r
iris[,1:4] %>%
Map(function (x, y) {
data.frame(
indicator = y,
tss = sum((x - mean(x))^2)
)
}, ., names(.)) %>%
Reduce(rbind, .) %>% {
ggplot(., aes(x = indicator, y = tss)) + geom_col()
} %T>%
print(.) %>%
ggsave("iris.png", .)
```
## Exposition pipe `%$%`
简单地讲,`L %$% R` 相当于 `with(L, R(...))` ,就是把 `L` 中的名字暴露给 `R` 去调用。比如要计算 Sepal.Length 和 Sepal.Width 的相关性,就可以这样
```r
iris %$% cor(Sepal.Length, Sepal.Width)
```
有的时候在调用基础包的一些函数时会比较有用。
## Assignment pipe `%<>%`
官方文档明确指出,使用该操作符 `L %<>% R` 相当于 `L <- L%>% R` ,所以个人觉得用处不大, 因为 `<-` 非常常用,而且含义也更明确,使用 `%<>%` 反而可读性降低了。
## Eager pipe `%!>%`
普通的 `%>%` 执行的是惰性运算,只有当需要进行计算的时候才进行计算。如果使用本地数据,这点可能体现的不是非常明显,当使用 **DBI** 连接到数据库的时候,会发现 **tidyverse** 中的函数(像 `select` `filter` `left_join` 等)实际上是拼接了一些 SQL 语句,当需要获取数据时(例如调用了 `collect()` 函数)才在数据库中执行。而 `%!>%` 运算符是即时执行的,每调用一次该运算符,都会进行数据的运算。这样当然结果会更加可预测。在一些特殊情况下,比如中间步骤需要展示一些警告信息,该操作符会比较有用。
感谢您的阅读。本网站「地与码之间」对本文保留所有权利。